
 English
English
Zadanie Współczynnik podobieństwa (sim)
Współczynnik podobieństwa
Limit pamięci: 32 MB
Bajtazar jest naukowcem zatrudnionym w Gdyńskim Centrum Biologii Obliczeniowej. Pracuje jako informatyk teoretyk i zajmuje się przede wszystkim projektowaniem efektywnych algorytmów operujących na napisach, wzorcach i tekstach... Ostatnio Bajtazar dostał zlecenie, aby przygotować program umożliwiający wyznaczanie współczynnika podobieństwa danego wzorca i tekstu.
Współczynnik ten oblicza się następująco. Wzorzec można dopasować do tekstu na wiele różnych sposobów. Interesują nas tylko takie konfiguracje, w których każda litera wzorca jest przyporządkowana do jakiejś litery tekstu. Ponadto, w dopasowaniu nie może być dziur, tzn. wzorzec musi zostać dopasowany do fragmentu tekstu o długości równej długości wzorca. Dla każdego takiego dopasowania wyznaczamy liczbę pozycji, na których litera wzorca jest taka sama jak odpowiadająca jej litera tekstu. Sumę tak obliczonych wartości nazywamy właśnie współczynnikiem podobieństwa wzorca i tekstu. Poniższa tabela przedstawia proces obliczania współczynnika podobieństwa przykładowego wzorca abaab oraz tekstu aababacab.
| Dopasowany fragment: | ||
| Tekst: | aababacab | aababacab |
| Wzorzec: |
abaab
abaab
abaab
abaab
abaab |
a..ab (3)
aba.. (3)
...a. (1)
aba.. (3)
...ab (2)
|
| Współczynnik podobieństwa: |
12 |
Bajtazar zdołał już przygotować interfejs graficzny swojego programu. Pomóż mu napisać fragment programu odpowiedzialny za obliczanie współczynników podobieństwa.
Wejście
W pierwszym wierszu standardowego wejścia znajduje się niepusty napis
złożony z małych liter alfabetu angielskiego - jest to wzorzec.
W drugim wierszu standardowego wejścia również znajduje się niepusty napis
złożony z małych liter alfabetu angielskiego - jest to tekst.
Możesz założyć, że długość wzorca nie przekracza długości tekstu.
Tekst składa się z co najwyżej 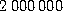 liter.
liter.
Dodatkowo, w testach wartych 30 punktów długość tekstu nie przekracza
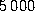 .
.
Wyjście
W pierwszym i jedynym wierszu standardowego wyjścia Twój program powinien wypisać jedną liczbę całkowitą: współczynnik podobieństwa wzorca i tekstu.
Przykład
Dla danych wejściowych:
abaab aababacab
poprawną odpowiedzią jest:
12
Wyjaśnienie: Przykład odpowiada tabeli z treści zadania.
Autor zadania: Jakub Pachocki.